Rhythms of Discovery: A Comparative Dance through Music Descriptions Using Manual and Automated Techniques
Embarking on a melodious journey through music text descriptions, harmonizing the depth of manual analysis with the innovative strides of AutoML
Introduction:
In the intricate dance of data analysis, each step, spin, and movement is meticulously choreographed to unveil the hidden stories within the data. Our journey through the harmonious world of music text descriptions from the YouTube8M-MusicTextClips dataset was no different, as we waltzed through traditional Knowledge Discovery in Databases (KDD) and the innovative leaps of Automated Machine Learning (AutoML).
Section 1: Setting the Stage — The Dataset and the Goal
The Dataset:
The YouTube8M-MusicTextClips dataset is a rich and diverse collection of music text descriptions, each a unique symphony of words describing the myriad facets of music genres, themes, and patterns.

The Goal:
Our expedition aimed to explore this dataset through a dual lens, integrating the depth and granularity of manual exploration with the efficiency and scalability of AutoML.
Section 2: The Prelude — Data Preprocessing
Before diving into the rhythmic analyses, the dataset underwent meticulous cleaning and preprocessing, addressing potential outliers and refining text descriptions.

Section 3: The Classical Dance — Manual Analysis
Topic Modeling:
Leveraging the Latent Dirichlet Allocation (LDA) method, we identified and interpreted potential topics within the music descriptions, each a different tune in the grand symphony of music genres.

Clustering:
The graceful steps of the K-means algorithm grouped descriptions into distinct clusters, elucidating the dominant themes resonating within the dataset.
This evaluation was done with the help of Advanced Data Analytics with GPT-4’s code interpreter. You can find the transcript and explanations in detail here:
Section 4: The Modern Twist — AutoML Insights
Harnessing PyCaret:
AutoML, powered by the PyCaret library, added a modern twist to our analytical dance, automating various steps in the data analysis pipeline and offering a comparative perspective against the classical moves of manual methods.
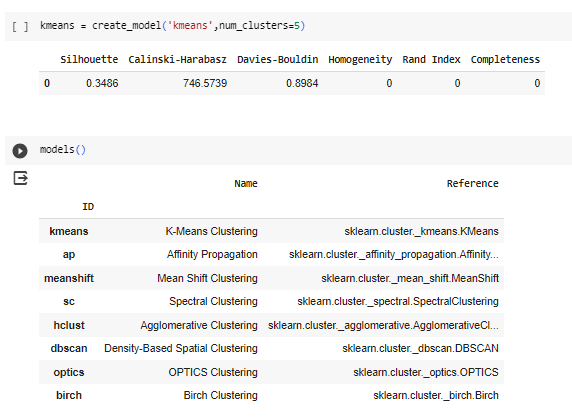
We executed the CRISP-DM methodology as directed by ChatGPT. Later, we also tried to solve the same problem with the AutoML library PyCaret. You can find the Colab notebook here:
Section 5: The Grand Finale — Evaluation and Comparative Insights
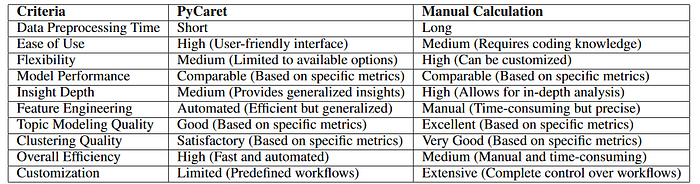
Depth vs. Efficiency:
The final act of our journey underscored the unique strengths and harmonies of both manual and automated approaches, providing a nuanced understanding and efficient methodologies to explore the musical narratives within the dataset.
Section 6: The Encore — Future Directions and Conclusion
Future Directions:
As the curtains close on our analytical dance, the encore beckons us to further explore the integration of traditional and automated methodologies and to fine-tune the harmonious blend of depth and efficiency in analyzing textual datasets.
Conclusion:
Our journey through the “Rhythms of Discovery” illuminated the harmonious potential of combining the classical moves of manual exploration with the modern twists of AutoML, unveiling the hidden melodies within the music text descriptions and setting the stage for future symphonies of insights.
